
The Disk Detective Database
We have a database! Thanks to a grant from the Space Telescope Science Institute, much of the Disk Detective science product is now available through the MAST archive.
What you’ll find there:
- Information on the classification data of individual objects from Disk Detective;
- Additional review information (literature review; more detailed examination) provided by members of the Disk Detective team;
- Cross-matches with Gaia, Pan-STARRS DR1, the TESS Input Catalog, and the APASS DR9 Catalog;
- Basic blackbody model SED fits to the observed data, with best-fit stellar effective temperature, disk temperature, and fractional infrared luminosity;
- Analysis of subjects from a convolutional neural network trained on Disk Detective classification data.
For more details on the information contained in each column, see below.
Original Selection Criteria
The original selection criteria to be included in Disk Detective were as follows (from Disk Detective Paper 1):
- w1mpro > 3.5 — WISE1 magnitude >3.5
- w4mpro < (w1mpro – 0.25) — WISE4 excess of 0.25 magnitudes over W1
- w1mpro > 5*sqrt((w1sigmpro*w1sigmpro)+(w4sigmpro*w4sigmpro)) + w4mpro — The W4 excess is significant at the 5-σ level
- w4sigmpro is not null and w4rchi2 < 1.3 — W4 profile-fitting yielded a fit with χ-squared < 1.3
- w4snr >=10 — W4 profile-fit signal-to-noise ratio > 10
- w4nm > 5 — Source detected at W4 in at least 5 individual 8.8s exposures with SNR > 3
- na = 0 and nb = 1 — The profile-fitting did not require active deblending
- n_2mass = 1 — One and onely one 2MASS PSC entries found within a 3″ radius of the W1 source position
- cc_flags[1] not matches “[DHOP]” and cc_flags[4] not matches “[DHOP]” — No diffraction spike, persistence, halo, or optical ghost issues at W1 or W4
- xscprox is null or xscprox > 30 — No 2MASS XSC source <30″ from the WISE source
- ext_flg = 0 — Photometry not contaminated by known 2MASS extended sources
Identifiers and Classification Data
The two primary identifiers used in the database are:
- designation: AllWISE ID
- ZooniverseID: unique ID for each target used in the Disk Detective back end
The raw classification data is broken into six categories, corresponding to the six options selectable by citizen scientists on the Disk Detective Web site. A screenshot of the classification page is shown below for reference.
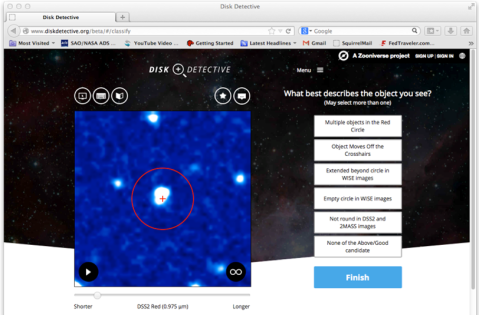
- good – “None of the Above/Good candidate”
- multi – “Multiple objects in the Red Circle”
- shift – “Object Moves Off the Crosshairs”
- extended – “Extended beyond circle in WISE images”
- empty – “Empty circle in WISE images”
- oval – “Not round in DSS2 and 2MASS images”
There are two other relevant status columns:
- classifiers – number of times a citizen scientist clicked “Finish” on a subject
- state – status on the website as of April 30, 2019
In addition, there are several “Fraction” columns (goodFraction, multiFraction, etc.). These are simply the number of votes in a category, divided by the number of classifiers for that object. So goodFraction = (good)/(classifiers), etc.
Vetting and literature review
In addition to classifications, we have a detailed literature review and re-evaluation by the team. The information from these is stored in three columns:
- flags – Objects flagged as having certain characteristics
- SciTeamFollowUp: whether or not we think the object is worth following up
- SciTeamComment: detailed comments explaining the decision in SciTeamFollowUp, including other literature references
Machine learning
Using Disk Detective classification data as a training set, we constructed a convolutional neural network to analyze Disk Detective images. The most useful results from this are listed in the “majGood” column.
- majGood: quality rating from a neural network trained on Disk Detective data.
Cross-matches
There are several cross-matches from Disk Detective to other surveys. These columns are generally denoted by a lower-case letter before the column name from that survey. We list these surveys below to demonstrate what prefix corresponds to which survey.
- pXXXXXX = data from PanSTARRS DR1
- gXXXXXX = data from Gaia DR2
- tXXXXXX = data from the TESS Input Catalog
- aXXXXXX = data from the AAVSO Photometric All-Sky Survey.
SED fits
SED fits for all objects are calculated using a maximum-likelihood estimator, using SciPy’s built-in minimize function from the optimize package. These SED fits take in as inputs the Gaia, 2MASS, and WISE photometry, and fit two blackbodies to the data, one each for the star and disk. For objects with more than two points of excess, a power-law fit is also calculated.
To view the SED for an object, click the thumbnail image in the row for that object in your search.
Results from these fits are also listed in columns.
- Tstar: best-fit blackbody stellar temperature
- Tdisk: best-fit blackbody disk temperature
- lir_lstar: best-fit fractional infrared luminosity.
NOTE: These SEDs are provided solely as a first-look estimate, to determine if a disk model is physically feasible (helping discern e.g. a background AGN), and should be interpreted with caution. In particular, blackbody fits are non-ideal for stellar temperatures below ~4000 K.
Acknowledgements
We thank Bernie Shiao, Geoff Wallace, and Justin Ely for their contributions to producing this database at MAST. We thank David Rodriguez for his work in implementing the SED fitting algorithm. Finally, we thank the ~30,000 citizen scientists whose contributions examining images of these objects by eye make up the bulk of our science product. In particular, we recognize citizen scientist Hugo A. Durantini Luca for his time and effort in beta-testing the database for use by the Disk Detective team and the rest of the field.
